library(tidyverse)
library(spotifyr)
library(highcharter)
library(ggridges)
library(DT)No dia 8 de maio o mundo da música ficou mais careta: Rita Lee, a rainha do rock brasileiro, padroeira da liberdade, a santa rita de sampa, nos deixou, mas não sem antes deixar um grande legado de obras, letras, frases.
O intuito desse artigo é homenagear Rita Lee a partir de uma análise de sua obra usando R. Das R-Ladies de São Paulo para a mais icônica “Mina de Sampa”.
Dica
Esse post contém alguns trocadilhos e referências musicais. Dá o play na playlist abaixo e chega mais, chega mais
Análise das músicas com spotifyR
Esse tal de R
Para começar, é preciso carregar alguns pacotes:
Primeiro, devemos configurar os dados da API do Spotify. Aqui tem um tutorialzinho explicando como obter seu Client ID e o token de acesso. No blog da Curso-R também mostra como criar seus tokens de acesso na API do Spotify (com o pacote Rspotify, que é diferente do que vamos usar aqui, mas o início é o mesmo!).
Com o ambiente configurado, podemos requisitar as características de áudio das faixas qualquer artista presente na plataforma! Isso é feito com a função get_artist_audio_features do pacote spotifyR.
Nessa análise, vamos coletar os atributos das faixas da Rita Lee e analisar alguns deles.
rita_features <- read_csv("data-raw/rita_features.csv")
glimpse(rita_features)
## Rows: 411
## Columns: 39
## $ artist_name <chr> "Rita Lee", "Rita Lee", "Rita Lee", "Rita…
## $ artist_id <chr> "7dnT2FUXhjirperXaH22IJ", "7dnT2FUXhjirpe…
## $ album_id <chr> "0rZu9DYrrdzdOUQ7Nm2QB8", "0rZu9DYrrdzdOU…
## $ album_type <chr> "album", "album", "album", "album", "albu…
## $ album_images <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
## $ album_release_date <chr> "2021-06-25", "2021-06-25", "2021-06-25",…
## $ album_release_year <dbl> 2021, 2021, 2021, 2021, 2021, 2021, 2021,…
## $ album_release_date_precision <chr> "day", "day", "day", "day", "day", "day",…
## $ danceability <dbl> 0.735, 0.802, 0.755, 0.821, 0.852, 0.656,…
## $ energy <dbl> 0.513, 0.638, 0.712, 0.769, 0.715, 0.734,…
## $ key <dbl> 2, 2, 5, 9, 0, 4, 2, 2, 5, 0, 0, 2, 6, 11…
## $ loudness <dbl> -9.369, -7.968, -7.696, -9.791, -8.402, -…
## $ mode <dbl> 1, 1, 1, 1, 1, 0, 1, 1, 0, 1, 1, 1, 0, 0,…
## $ speechiness <dbl> 0.0299, 0.0319, 0.0397, 0.0707, 0.0427, 0…
## $ acousticness <dbl> 0.031100, 0.005490, 0.000466, 0.001490, 0…
## $ instrumentalness <dbl> 0.414000, 0.023400, 0.258000, 0.726000, 0…
## $ liveness <dbl> 0.1160, 0.2160, 0.2210, 0.0469, 0.0426, 0…
## $ valence <dbl> 0.5470, 0.6850, 0.8350, 0.4380, 0.6770, 0…
## $ tempo <dbl> 119.978, 127.982, 127.986, 125.000, 123.0…
## $ track_id <chr> "4CFOKrbwh1FuR5xBvOWG2R", "1VM1W9cMkrHmrX…
## $ analysis_url <chr> "https://api.spotify.com/v1/audio-analysi…
## $ time_signature <dbl> 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4,…
## $ artists <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
## $ available_markets <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
## $ disc_number <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,…
## $ duration_ms <dbl> 356886, 216585, 369843, 524638, 320488, 2…
## $ explicit <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE,…
## $ track_href <chr> "https://api.spotify.com/v1/tracks/4CFOKr…
## $ is_local <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE,…
## $ track_name <chr> "Só De Você - Coppola Remix", "Pega Rapaz…
## $ track_preview_url <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
## $ track_number <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13…
## $ type <chr> "track", "track", "track", "track", "trac…
## $ track_uri <chr> "spotify:track:4CFOKrbwh1FuR5xBvOWG2R", "…
## $ external_urls.spotify <chr> "https://open.spotify.com/track/4CFOKrbwh…
## $ album_name <chr> "Rita Lee & Roberto - Classix Remix Vol. …
## $ key_name <chr> "D", "D", "F", "A", "C", "E", "D", "D", "…
## $ mode_name <chr> "major", "major", "major", "major", "majo…
## $ key_mode <chr> "D major", "D major", "F major", "A major…Aqui já conseguimos ver que o dataframe resultante dessa requisição tem 39 colunas e 411 linhas, que correspondem a cada faixa da cantora. Há uma coluna com o formato errado, a album_release_date, que é a data de lançamento do álbum (não usaremos esse atributo na análise, mas é bom saber :D)
Importante
Alguns álbuns são homônimos (ou seja, têm o mesmo nome), são coletâneas e/ou remixes. Tem que considerar isso na análise!
Quantas faixas cada álbum tem? Há algumas maneiras de fazer isso, mas vou utilizar o “GSA” (as funções group_by,summarise e arrange do pacote dplyr):
rita_features |>
group_by(album_name, album_release_year) |>
summarise(faixas=n()) |>
arrange(desc(faixas)) |>
datatable(extensions = c('FixedColumns',"FixedHeader"),
options = list(
scrollX = FALSE,
paging=TRUE,
fixedHeader=TRUE,
class = (c('compact', 'row-border', "hover", "nowrap" ))
),
caption="Tabela 1 - Quantidade de faixas por álbum")O “Em Bossa ’N Roll (Edição Comemorativa - 25 Anos) - Ao Vivo” é o álbum com mais faixas entre todos os discos listados no Spotify.
Será que isso significa que o “Em Bossa ’N Roll (Edição Comemorativa - 25 Anos) - Ao Vivo” é o álbum mais longo? Para responder a essa pergunta, podemos somar a duração em milissegundos de cada álbum, medida pelo atributo duration_ms.
rita_features |>
group_by(album_name, album_release_year) |>
summarise("duracao" = sum(duration_ms)) |>
arrange(desc(duracao)) |>
datatable(extensions = c('FixedColumns',"FixedHeader"),
options = list(scrollX = FALSE, paging=TRUE, fixedHeader=TRUE,
class = (c('compact', 'row-border', "hover", "nowrap" ))),
caption="Tabela 2 - Duração de cada álbum da Rita Lee, em milissegundos")Quase! É de se imaginar que os álbuns ao vivo, coletâneas e remixes apareçam com mais faixas e maior duração (no ao vivo tem o bis, a interação com o público…)
Para evitar problemas com álbuns homônimos, criei uma nova coluna incluindo “nome do álbum - ano de lançamento”.
rita_features <- rita_features |>
mutate(album = paste(album_name, "-", album_release_year))Para as próximas análises, vamos considerar apenas os álbuns da discografia em estúdio da Rita Lee, de acordo com Wikipedia. Criei um novo objeto, o rita_filtrado só com essa lista.
rita_filtrado <- subset(rita_features, album_name %in% c('Build Up', 'Hoje É O Primeiro Dia Do Resto Da Sua Vida', 'Atrás Do Porto Tem Uma Cidade', 'Fruto Proibido', 'Entradas E Bandeiras', 'Babilônia', 'Rita Lee', 'Rita Lee', 'Saúde', 'Flagra', 'Bombom', 'Rita E Roberto', 'Flerte Fatal', 'Zona Zen', 'Rita Lee E Roberto De Carvalho', 'Rita Lee', 'Santa Rita De Sampa', 'Rita Lee 3001', 'Aqui, Ali, Em Qualquer Lugar','Balacobaco','Reza'))“Mas louco é quem me diz e não é feliz”
A positividade de uma canção pode ser medida com a valência dela. De acordo com a documentação da API do Spotify, valência “é uma medida de 0.0 a 1.0 que descreve a positividade musical transmitida por uma faixa. Faixas com alta valência soam mais positivas (por exemplo, felizes, alegres, eufóricas), enquanto faixas com baixa valência soam mais negativas (por exemplo, tristes, deprimidas, irritadas)”.
Então quais são as músicas mais e menos positivas da Rita?
# Mais positiva
rita_filtrado$track_name[which.max(rita_filtrado$valence)]
## [1] "Tatibitati"
# Menos positiva
rita_filtrado$track_name[which.min(rita_filtrado$valence)]
## [1] "Eu e Mim"A música “Tabitati”, do álbum “Saúde”, é a mais positiva entre todas as faixas que estamos analisando. Por outro lado, a menos positiva é a “Eu e Mim”.
Quero ver qual é o álbum mais positivo. Para isso, escolhi a mediana da valência de cada álbum para representar esse atributo:
rita_filtrado |>
group_by(album) |>
summarise_at(vars(valence), list(mediana=median)) |>
arrange(desc(mediana)) |>
datatable(extensions = c('FixedColumns',"FixedHeader"),
options = list(scrollX = FALSE, paging=TRUE, fixedHeader=TRUE,
class = (c('compact', 'row-border', "hover", "nowrap" ))),
caption="Tabela 3 - Mediana da valência de cada álbum da Rita Lee")Podemos representar a distribuição do atributo valência em cada álbum visualmente:
rita_filtrado |>
arrange(album_release_year) |>
mutate(album=factor(album, levels = rev(unique(rita_filtrado$album)))) |>
ggplot(aes(x= valence, y= album, fill= album)) +
geom_density_ridges(from = 0, to = 1, alpha = 1, size = 0.1) +
labs(
x = "Escala de valência",
y = "",
title = "Distribuição da postividade das músicas de Rita Lee por álbum",
subtitle = "Valência: Faixas com maiores níveis de valência soam mais positivas e vice-versa",
caption = "por Bianca Muniz (@biancamuniz__) | Fonte: Spotify's Web API"
) +
scale_fill_cyclical(
values = c("#9A373F")
) +
theme_ridges() +
theme(
plot.title = element_text(hjust = 0.5, size = 12, color = "#000000", face = "bold", family = "Bitter"),
plot.title.position = "plot",
plot.subtitle = element_text(face = "italic", hjust = 0.5, size = 10, family = "Bitter"),
axis.text.y = element_text(size = 10, family = "Raleway"),
axis.title.x = element_text(hjust = 0.5, size = 11, family = "Raleway"),
plot.caption = element_text(size = 9, family = "Bitter"))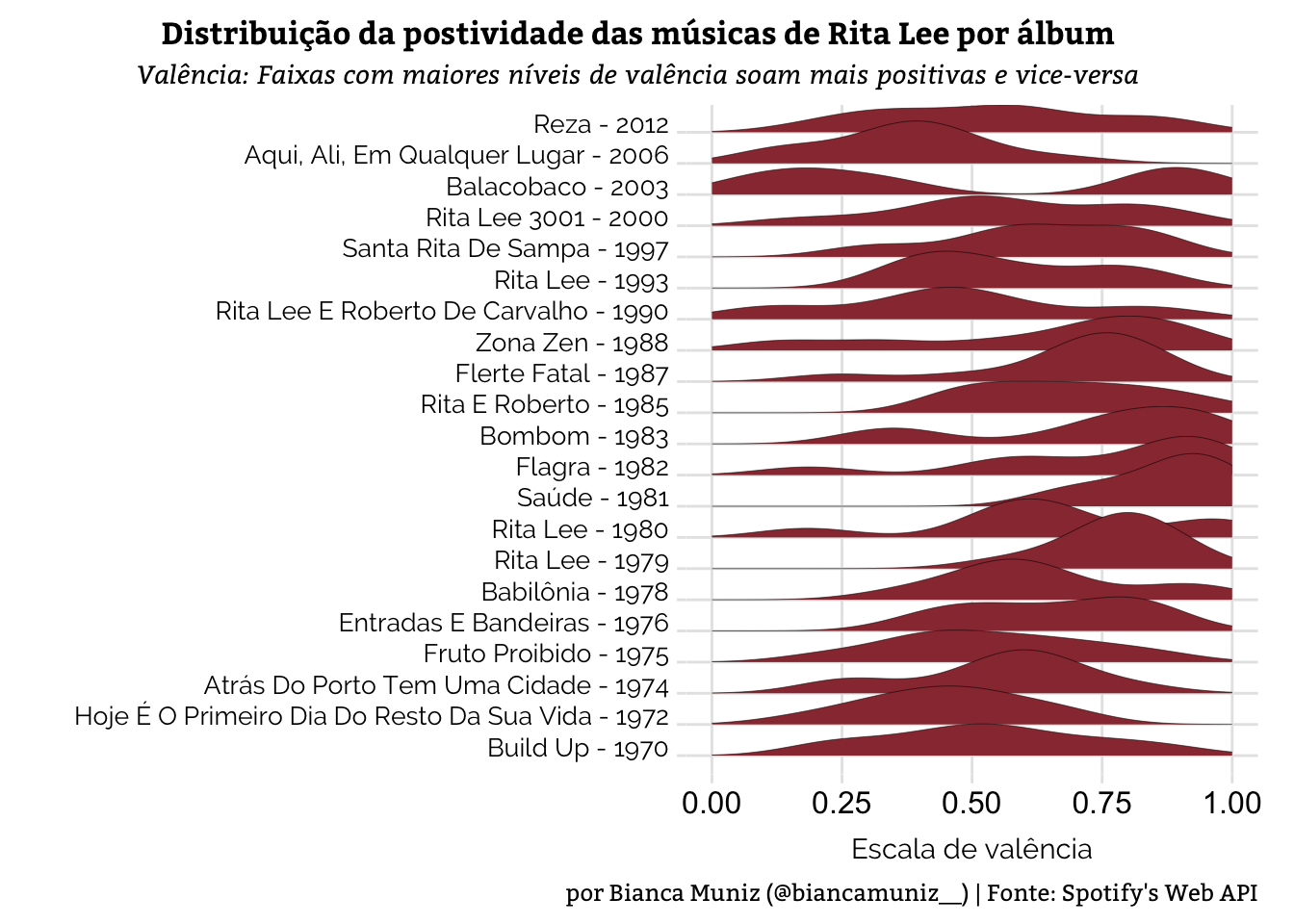
O gráfico mostra “uma onda” por álbum da Rita. Os picos são os valores com mais faixas naquele ponto da escala de valência.
Olhando o gráfico, dá para perceber que os anos de 1981 e 1983 foram mais positivos musicalmente, de acordo com os atributos dos álbuns lançados nesses anos.
“Pra pedir silêncio eu berro, pra fazer barulho eu mesma faço”
Vamos analisar a energia das músicas da rainha do rock. Diferentemente da energia espiritual e cósmica que uma padroeira da liberdade poderia exalar, a API descreve esse atributo como “uma escala de 0 a 1 e representa uma medida de intensidade e atividade. Normalmente, as faixas energéticas parecem rápidas, altas e barulhentas”. Isso significa que uma faixa bem pesada, como um death metal, teria alta energia, enquanto uma baladinha suave pontua baixo na escala.
rita_filtrado |>
arrange(album_release_year) |>
mutate(album=factor(album, levels = rev(unique(rita_filtrado$album)))) |>
ggplot(aes(x= energy, y= album, fill= album))+
geom_density_ridges(from = 0, to = 1, alpha = 1, size = 0.1) +
labs(x = "Escala de energia", y = "",
title = "Distribuição da energia das músicas de Rita Lee por álbum",
subtitle = "Energia: Faixas com maiores níveis de energia são mais rápidas e altas e vice-versa",
caption = "por Bianca Muniz (@biancamuniz__) | Fonte: Spotify's Web API") +
scale_fill_cyclical(values = c("#9A373F")) +
theme_ridges()+
theme(
plot.title = element_text(hjust = 0.5, size = 12, color = "#000000", face = "bold", family = "Bitter"),
plot.title.position = "plot",
plot.subtitle = element_text(face = "italic", hjust = 0.5, size = 10, family = "Bitter"),
axis.text.y = element_text(size = 10, family = "Raleway"),
axis.title.x = element_text(hjust = 0.5, size = 11, family = "Raleway"),
plot.caption = element_text(size = 9, family = "Bitter"))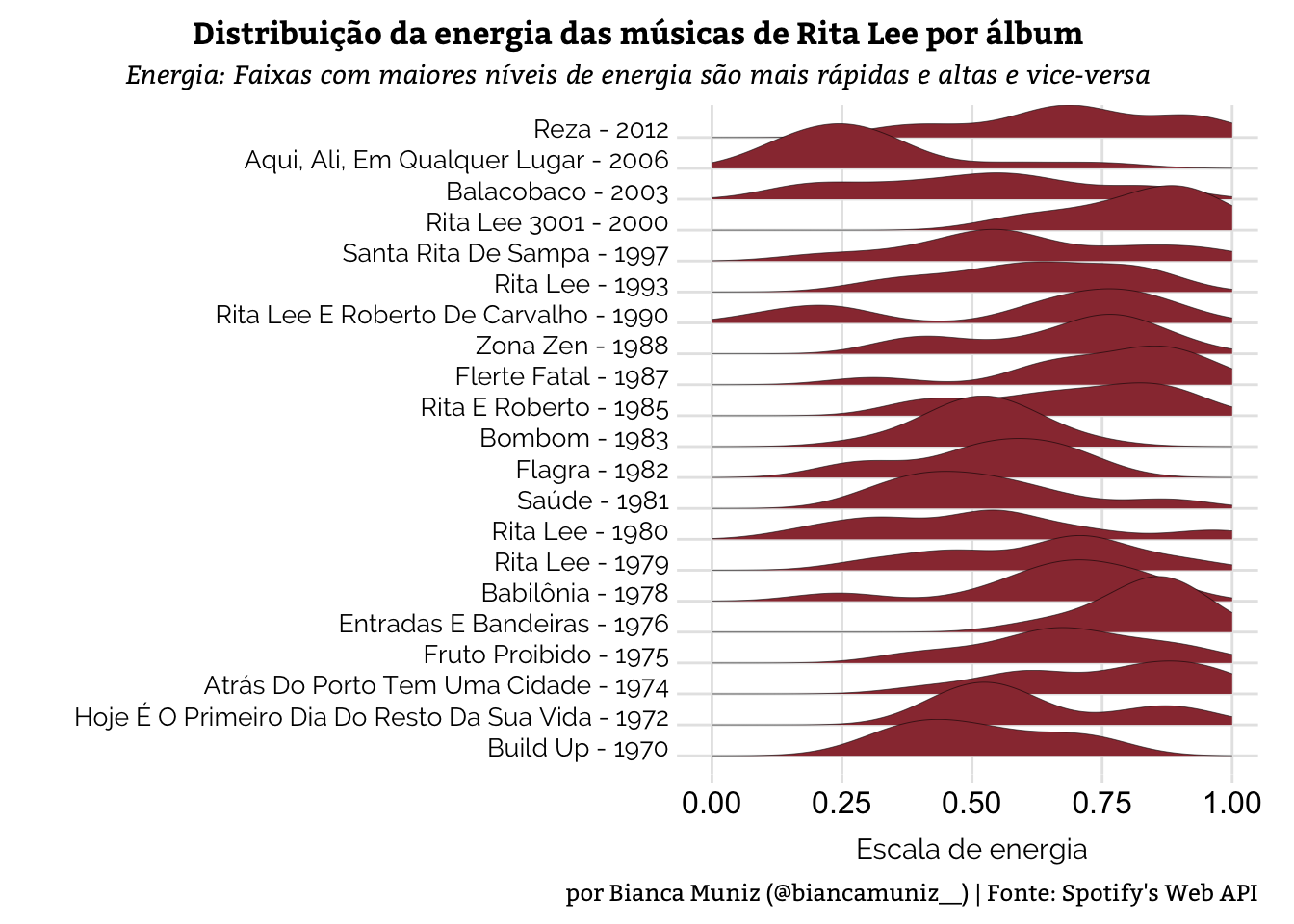
Olhando a representação visual, o “Aqui, Ali, em Qualquer Lugar” aparece como o álbum menos energético, com mais faixas próximas do 0. Lançado em 2006, ele tá cheio de versões de músicas dos Beatles.
Aprofundando na análise, o próximo passo é ver quais as músicas com mais energia:
rita_filtrado |>
select(track_name, album_name, energy) |>
top_n(5) |>
arrange(-energy) |>
datatable(extensions = c('FixedColumns',"FixedHeader"),
options = list(scrollX = FALSE, paging=TRUE, fixedHeader=TRUE,
class = (c('compact', 'row-border', "hover", "nowrap" ))),
caption='Tabela 3 - Músicas mais energéticas')Aqui temos um empate entre “Erva Venenosa” e “Tratos À Bola”. Vou trapacear na minha própria análise e colocar o link de “Orra Meu”, minha faixa favorita entre o top 5 de músicas mais energéticas. Rita me perdoaria, eu acho.
“Baila comigo”
O atributo dançabilidade (“danceability” em inglês - confesso não saber de uma palavra em português pra isso) descreve o quão adequada uma faixa é para dançar, baseado em uma combinação de elementos musicais incluindo tempo, estabilidade rítmica, força do beat e regularidade geral. Um valor de 0 é o menos dançável e 1 é o mais dançável.
Desse modo, vamos ver qual faixa tem o valor máximo de danceabilidade:
rita_filtrado$track_name[which.max(rita_filtrado$danceability)]
## [1] "A Fulana"“A Fulana” é a mais adequada para dançar “lá no meu esconderijo”. Concorda?
Veja como a dançabilidade se mostra nos álbuns de Rita: primeiro, com a mediana do atributo por álbum e depois com o gráfico:
rita_filtrado |>
group_by(album) |>
summarise_at(vars(danceability), list(danceabilidade=median)) |>
arrange(desc(danceabilidade)) |>
datatable(extensions = c('FixedColumns',"FixedHeader"),
options = list(scrollX = FALSE, paging=TRUE,fixedHeader=TRUE,
class = (c('compact', 'row-border', "hover", "nowrap" ))),
caption="Tabela 4 - Mediana da dançabilidade de cada álbum da Rita Lee")rita_filtrado |>
arrange(album_release_year) |>
mutate(album=factor(album, levels = rev(unique(rita_filtrado$album)))) |>
ggplot(aes(x= danceability, y= album, fill= album)
)+
geom_density_ridges(from = 0, to = 1, alpha = 1, size = 0.1) +
labs(
x = "Escala de dançabilidade",
y = "",
title = "Distribuição da dançabilidade das músicas de Rita Lee por álbum",
subtitle = "Essa escala mede as músicas mais ou menos dançáveis",
caption = "por Bianca Muniz (@biancamuniz__) | Fonte: Spotify's Web API"
) +
scale_fill_cyclical(values = c("#9A373F")) +
theme_ridges()+
theme(
plot.title = element_text(hjust = 0.5, size = 12, color = "#000000", face = "bold", family = "Bitter"),
plot.title.position = "plot",
plot.subtitle = element_text(face = "italic", hjust = 0.5, size = 10, family = "Bitter"),
axis.text.y = element_text(size = 10, family = "Raleway"),
axis.title.x = element_text(hjust = 0.5, size = 11, family = "Raleway"),
plot.caption = element_text(size = 9, family = "Bitter"))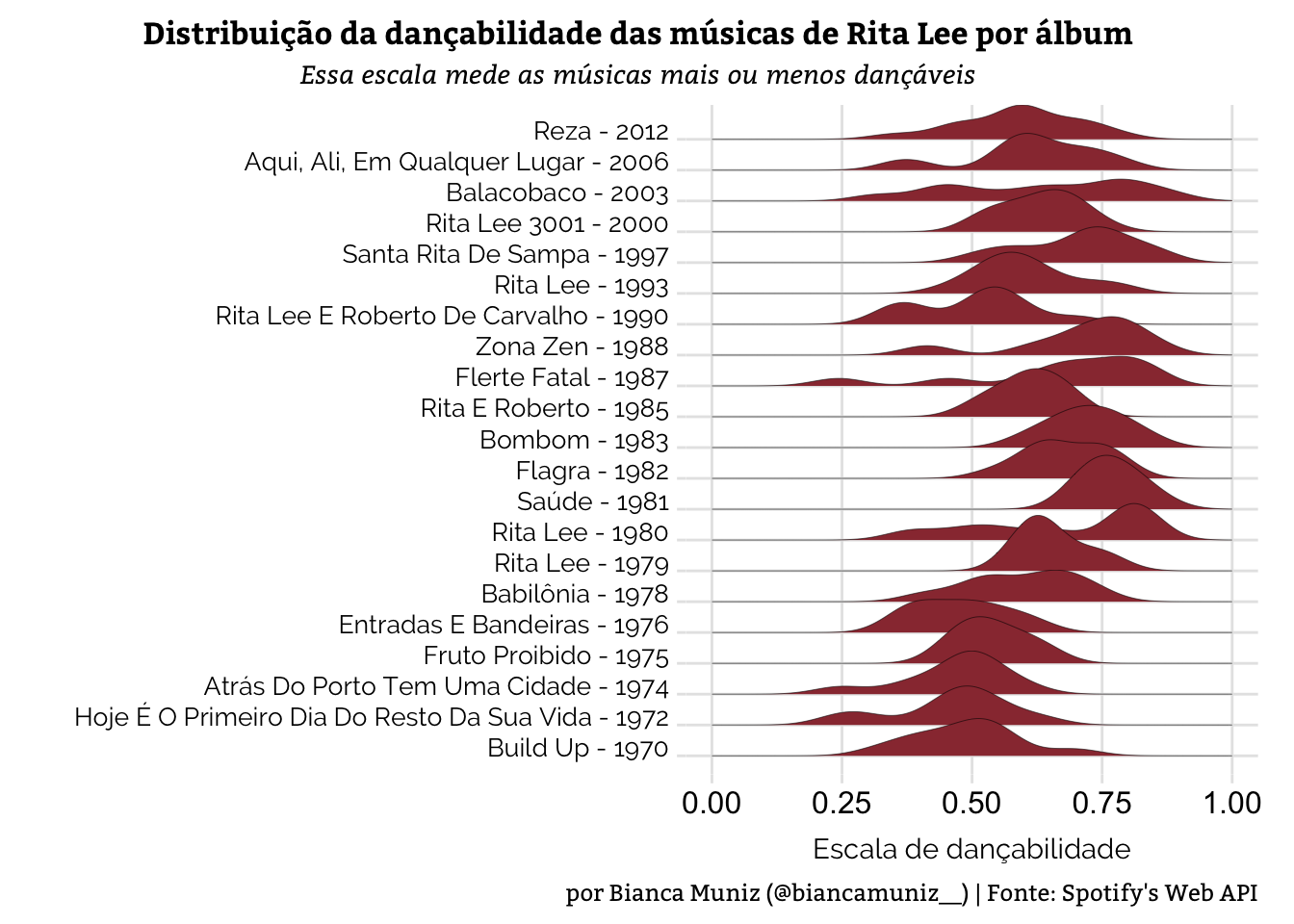
“E falo baixo nos meus decibéis”
Os atributos fala (speechiness) e instrumentalidade (instrumentalness) podem se complementar. Enquanto o primeiro trata da detecção da presença de palavras faladas em uma faixa musical, o segundo prevê se uma faixa não contém vocais.
De acordo com o Spotify, “Quanto mais exclusivamente falado for o registro (por exemplo, programa de entrevista, audiolivro, poesia), mais próximo de 1.0 será o valor do atributo [fala]. Já na instrumentalidade,”sons de”ooh” e “aah” são tratados como instrumentais nesse contexto. Quanto mais próximo o valor de instrumentalidade for de 1.0, maior a probabilidade de a faixa não conter conteúdo vocal. Valores acima de 0.5 pretendem representar faixas instrumentais, mas a confiança é maior à medida que o valor se aproxima de 1.0”
Olhando as músicas mais/menos faladas e as mais/menos instrumentais:
# Mais falada
rita_filtrado$track_name[which.max(rita_filtrado$speechiness)]
## [1] "Pistis Sophia"
# Menos falada
rita_filtrado$track_name[which.min(rita_filtrado$speechiness)]
## [1] "Pirarucu"# Mais instrumental
rita_filtrado$track_name[which.max(rita_filtrado$instrumentalness)]
## [1] "De Novo Aqui Meu Bom José"
# Menos instrumental
rita_filtrado$track_name[which.min(rita_filtrado$instrumentalness)]
## [1] "Pistis Sophia"É interessante observar que nesse caso os atributos se complementam quando observamos a música “Pistis Sophia”, cuja letra é uma oração à Nossa Senhora Aparecida. Ela é a menos instrumental e a com maior presença vocal.
Análise das letras
Raspagem com uma cobra cascavel
Antes de passar para o R, vamos fazer a raspagem do site letras.mus.br com Python (aquela linguagem do logo de cobrinha). Para isso, é preciso importar algumas bibliotecas:
import requests
from bs4 import BeautifulSoup
import pandas as pdA url utilizada será a da página da Rita no site:
url = 'https://www.letras.mus.br/rita-lee/'O bloco de código abaixo explica a raspagem da página: quero que encontre o link para cada música na página da Rita Lee e a letra correspondente a cada canção. O código forma uma tabela, com as colunas “nome” (nome da música) e “verso”. Cada linha é um verso das músicas coletadas.
No final, salva o resultado em um arquivo CSV pra analisarmos com R!
# Realiza a requisição HTTP para obter o HTML da página
response = requests.get(url)
# Faz o parsing do HTML com o BeautifulSoup
soup = BeautifulSoup(response.text, 'html.parser')
# Encontra todos os links das músicas
links = soup.find_all('a', class_='song-name')
# Cria um DataFrame vazio com as colunas 'nome' e 'verso'
df = pd.DataFrame(columns=['nome', 'verso'])
for link in links:
song_url = link['href']
song_url2 = "https://www.letras.mus.br"+ song_url
song_title = link.text.strip()
song_response = requests.get(song_url2)
song_soup = BeautifulSoup(song_response.text, 'html.parser')
lyrics_div = song_soup.find('div', class_='cnt-letra')
if lyrics_div is not None:
# Extrai cada verso da letra e adiciona como uma nova linha no DataFrame
verses = list(lyrics_div.stripped_strings)
data = {'nome': [song_title] * len(verses), 'verso': verses}
df = pd.concat([df, pd.DataFrame(data)], ignore_index=True)
else:
print(f"Não foi possível encontrar a letra da música '{song_title}'.")
# Salva o DataFrame em um arquivo CSV
#df.to_csv('data-raw/rita-letras.csv')Voltando para o R (tenho mais facilidade com ele) vamos carregar mais alguns pacotes úteis para o trabalho com textos e importar o arquivo com as letras:
library(stopwords)
library(tm)
library(tidytext)
library(wordcloud2)
letras <- read.csv("data-raw/rita-letras.csv")
glimpse(letras)
## Rows: 7,718
## Columns: 3
## $ X <int> 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18…
## $ nome <chr> "2001", "2001", "2001", "2001", "2001", "2001", "2001", "2001", …
## $ verso <chr> "Astronauta libertado", "Minha vida me ultrapassa", "Em qualquer…O dataframe tem três colunas e mais de 7 mil linhas! Vamos olhar qual a música com mais versos:
letras |>
group_by(nome) |>
summarise(qtd_de_versos=n()) |>
arrange(desc(qtd_de_versos)) |>
datatable(extensions = c('FixedColumns',"FixedHeader"),
options = list(scrollX = FALSE, paging=TRUE, fixedHeader=TRUE,
class = (c('compact', 'row-border', "hover", "nowrap" ))),
caption="Tabela 5 - Quantidade de versos por música na página da Rita Lee no site letras.mus.br")
Importante
A página lista covers feito pela artista, ao vivo ou em álbuns. Considerar isso nas análises!
A música com mais versos no site é “Bad”, originalmente cantada por Michael Jackson. Rita Lee já homenageou o astro do pop ao vivo com um cover. Desconsiderando “Bad”, a música da Rita com mais versos é “Mutante”. “Ai de mim que sou romântica”…
“O som das nuvens” (de palavras)
Antes de analisar o texto, é preciso fazer uma série de ajustes, um pré-processamento. Aqui vamos deixar as letras em minúscula, faremos a remoção de algumas palavras (as stopwords) e o processo de tokenização.
Convertendo todo o texto da coluna “verso” para letras minúsculas:
letras <- letras |>
mutate(verso = tolower(verso))Stopwords são palavras comuns que geralmente são consideradas irrelevantes para a análise de conteúdo e podem incluir pronomes, artigos, preposições e conjunções, etc. O objetivo de filtrar essas palavras é diminuir o conteúdo a ser analisado e melhorar sua eficiência.
No dataframe com as letras há músicas em português e em inglês. O código abaixo cria um vetor chamado “my_stopwords” que contém stopwords nos dois idiomas, que a gente vai remover mais pra frente:
my_stopwords <- c(stopwords("en"), stopwords("pt"))A tokenização é um processo de dividir um texto em unidades menores, chamadas tokens. Esses tokens podem ser palavras únicas, frases, duplas de palavras, partes de palavras, dependendo do nível de granularidade desejado. O código abaixo divide cada verso em um token (que neste caso, é a palavra):
tidy_letras <- letras
tidy_letras <- tidy_letras |>
unnest_tokens(palavra, verso)
tidy_letras|>
datatable(extensions = c('FixedColumns',"FixedHeader"),
options = list(scrollX = FALSE, paging=TRUE,fixedHeader=TRUE,
class = (c('compact', 'row-border', "hover", "nowrap" ))),
caption="Tabela 6 - Músicas de Rita Lee, tokenizadas por palavra")Removendo as stopwords e linhas em branco:
tidy_letras$palavra <- removeWords(tidy_letras$palavra, my_stopwords)
tidy_letras <- subset(tidy_letras, palavra != "")wordcloud <- tidy_letras |>
group_by(palavra) |>
summarise(ocorrências = n()) |>
arrange(desc(ocorrências))
wordcloud <- na.omit(wordcloud)Agora os dados estão prontos para formar a nuvem de palavras com os termos mais frequentes nas letras!
wordcloud |>
filter(ocorrências > 10) |>
wordcloud2(size = 1, minSize = 0.8, gridSize = 1,
fontFamily = 'Bitter', fontWeight = 'bold',
color = "#9A373F",
backgroundColor = "white",
minRotation = -pi/4, maxRotation = pi/4, shuffle = FALSE,
rotateRatio = 0, shape = 'circle', ellipticity = 1,
widgetsize = NULL, figPath = NULL, hoverFunction = NULL)As palavras mais frequentes, no formato de tabela:
wordcloud |> datatable(extensions = c('FixedColumns',"FixedHeader"),
options = list(scrollX = FALSE, paging=TRUE, fixedHeader=TRUE,
class = (c('compact', 'row-border', "hover", "nowrap" ))),
caption="Tabela 7 - Quantidade de palavras nas música da página da Rita Lee")Uma outra forma de analisar os versos é mudar o token: ao invés de palavras, vamos usar bigramas como tokens. Bigrama é um termo usado em linguística e processamento de linguagem natural para se referir a uma sequência de dois itens, geralmente palavras. Em outras palavras, um bigrama é um par ordenado de palavras consecutivas em um texto. É útil para tentar entender o contexto que uma palavra tá inserida.
Abaixo, os bigramas mais frequentes nos versos, desconsiderando as stopwords:
bigrama_letras <- letras
bigramas_rita <- bigrama_letras |>
select(nome, verso) |>
unnest_tokens(bigram, verso, token = "ngrams", n = 2) |>
separate(bigram, c("word1", "word2"), sep = " ") |>
filter(!word1 %in% my_stopwords) |>
filter(!word2 %in% my_stopwords) |>
subset(word1 != "") |>
subset(word2 != "") |>
mutate(bigrama = paste(word1, word2, sep = " "))
bigramas_rita <- unique(bigramas_rita)
bigramas_rita2 <- bigramas_rita |>
dplyr::count(bigrama, sort = TRUE)
ggplot(head(bigramas_rita2,20), aes(reorder(bigrama,n), n)) +
geom_bar(stat = "identity", fill = "#9A373F") + coord_flip() +
labs(
x = "",
title = "Bigramas mais frequentes",
caption = "por Bianca Muniz (@biancamuniz__) | Fonte: letras.mus.br"
)+
theme_minimal()+
theme(
plot.background = element_rect(fill = "white", colour = "white"),
panel.background = element_rect(fill = "white", colour = "white"),
plot.title=element_text(hjust = 0.5, size = 20, color = "#000000", face="bold", family = "Bitter"),
plot.title.position = "plot",
plot.caption = element_text(size=10, family = "Bitter"),
plot.subtitle=element_text(face="italic", hjust = 0.5, size=16, family = "Raleway"),
axis.text.y = element_text(size = 10, face="bold", family = "Raleway"),
axis.text.x = element_blank(), # Remove os valores do eixo x
axis.ticks.x = element_blank(), # Remove as marcações do eixo x
axis.title.x = element_blank(), # Remove o título do eixo x
panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
panel.border = element_blank(),
axis.line = element_blank()
) +
geom_text(aes(label=n), hjust=-0.5, size=4, family = "Bitter") 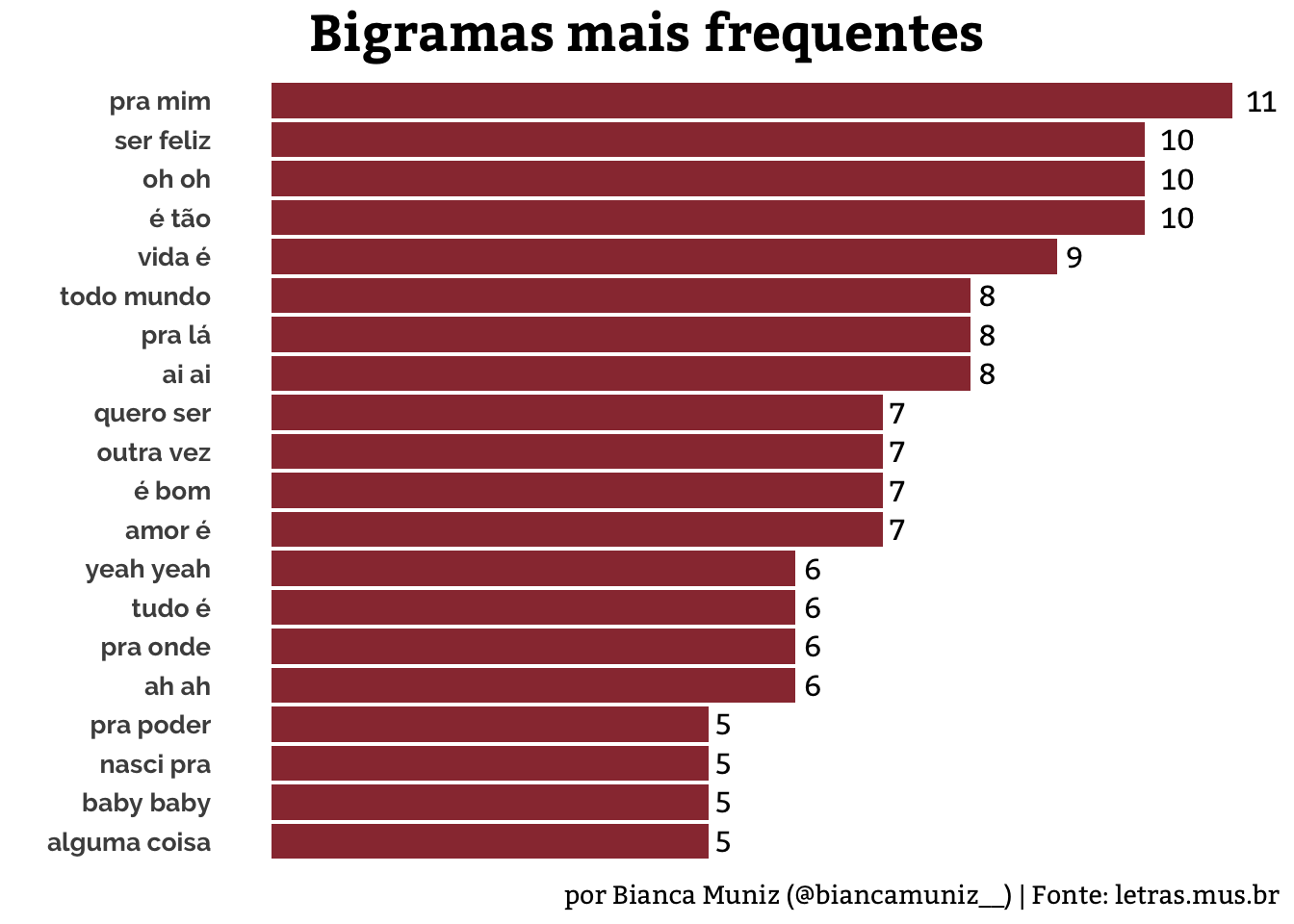
Os “oh oh”, “ai ai”, “yeah yeah”, “ah ah” poderiam ser acrescentados às stopwords. Resolvi deixar depois de lembrar de uma entrevista da Rita no programa Altas Horas, em que ela fala desses “uououou” como parte da sua “vocação” para backing vocal.

Para ter mais ideia do contexto no qual esses bigramas se inserem, vamos detectá-los nos versos e exibir o verso inteiro. Para isso, primeiro a gente retira a pontuação da coluna verso, para que isso não atrapalhe na detecção de bigramas separados por um ponto, vírgula, etc:
# Remover pontuação da coluna "texto"
letras$verso_limpo <- gsub("[[:punct:]]", "", letras$verso)Olhando como o bigrama mais frequente, “pra mim”, se insere nas frases:
letras |>
filter(str_detect(verso_limpo, "pra mim")) |>
select(X, nome, verso) |>
datatable(extensions = c('FixedColumns',"FixedHeader"),
options = list(scrollX = FALSE, paging=TRUE, fixedHeader=TRUE,
class = (c('compact', 'row-border', "hover", "nowrap" ))),
caption='Tabela 8 - Bigrama "pra mim" inserido em versos')As palavras “tão”, “tudo” e “todo” têm em comum o fato de serem palavras relacionadas à quantidade ou extensão de algo. Podemos inferir um sentido de intensidade e/ou generalização. Será isso mesmo?
letras |>
filter(str_detect(verso_limpo, "é tão")) |>
select(X, nome, verso) |>
datatable(extensions = c('FixedColumns',"FixedHeader"),
options = list(scrollX = FALSE, paging=TRUE,fixedHeader=TRUE,
class = (c('compact', 'row-border', "hover", "nowrap" ))),
caption='Tabela 9 - Bigrama "é tão" inserido em versos')letras |>
filter(str_detect(verso_limpo, "todo mundo")) |>
select(X, nome, verso) |>
datatable(extensions = c('FixedColumns',"FixedHeader"),
options = list(scrollX = FALSE, paging=TRUE,fixedHeader=TRUE,
class = (c('compact', 'row-border', "hover", "nowrap" ))),
caption='Tabela 10 - Bigrama "todo mundo" inserido em versos')letras |>
filter(str_detect(verso_limpo, "tudo é")) |>
select(X, nome, verso) |>
datatable(extensions = c('FixedColumns',"FixedHeader"),
options = list(scrollX = FALSE, paging=TRUE,fixedHeader=TRUE,
class = (c('compact', 'row-border', "hover", "nowrap" ))),
caption='Tabela 11 - Bigrama "tudo é" inserido em versos')Tomados em conjunto, penso num reflexo da “porralouquice” de Rita, de seu comportamento intenso.

“Ser feliz” é o segundo bigrama mais frequente. Nos versos, ele aparece assim:
letras |>
filter(str_detect(verso_limpo, "ser feliz")) |>
select(X, nome, verso) |>
datatable(extensions = c('FixedColumns',"FixedHeader"),
options = list(scrollX = FALSE, paging=TRUE,fixedHeader=TRUE,
class = (c('compact', 'row-border', "hover", "nowrap" ))),
caption='Tabela 12 - Bigrama "ser feliz" inserido em versos')“…um monte de gente feliz”
É difícil pensar em considerações finais sobre um legado tão vasto e uma pessoa tão cheia de adjetivos. Mas Rita pensou e acho que não há palavras melhores que as dela para finalizar esse post:
